합성곱 신경망 기반 분류 모델의 화재 예측 성능 분석
Analysis of Fire Prediction Performance of Image Classification Models based on Convolutional Neural Network
Article information
Abstract
본 연구에서는 화재 안전 향상을 위한 엣지 컴퓨팅(edge computing) 기반 화재감지시스템에 적용 가능한 합성곱 신경망 기반 이미지 분류 모델들인 MobileNetV2, ResNet101, EfficientNetB0를 이용하여 화재 예측 성능 해석을 수행하였다. 성능평가지표인 정확도, 재현율, 정밀도, F1-score와 혼동 행렬을 이용하여 화재 예측 성능을 비교 분석하였다. 또한 분류 모델의 경량화와 관련한 모델 용량 및 추론시간에 대한 비교 분석을 수행하였다. 비교 분석 결과로서 화재 예측 정확도는 EfficientNetB0 모델이 가장 높았으며 경량성 측면에서는 MobileNetV2가 가장 우수한 것으로 확인하였다. 더하여 화재와 유사한 특징을 갖는 비 화재 이미지인 빛과 연무에 대한 이미지 특성을 추가 학습한 결과, 경량성은 우수하나 예측 성능이 낮은 MobileNetV2의 화재 예측 정확도가 개선되는 것을 확인하였다.
Trans Abstract
In this study, fire prediction performance was analyzed using convolutional neural network (CNN)-based classification models such as MobileNetV2, ResNet101, and EfficientNetB0 applicable to an edge computing-based fire detection system for improving fire safety. The fire prediction performance was evaluated using the performance evaluation measures including accuracy, recall, precision, F1-score, and the confusion matrix. The model size and inference time were assessed in terms of the light-weight classification model for the practical deployment and use. The analysis results confirmed that the EfficientNetB0 model had the highest fire prediction accuracy, and the MobileNetV2 was the best light-weight classification model. Notably, additionally learning the image features about light and haze images having similar features with those of the fire images improved the fire prediction accuracy of the light-weight MobileNetV2 model.
1. 서 론
최근 도시화, 밀집화, 고층화 등의 영향으로 복합적이고 대규모적인 화재안전사고가 많이 발생하고 있다. 이러한 화재안전사고는 대규모의 인명 및 재산 피해를 야기하기 때문에 화재발생 초기에 발견하고 진압하여 그 피해를 최소화해야 한다. 이를 위해 자동화재경보시스템의 화재감지기술에 대한 관심이 증대되고 있으며 고성능화, 소형화, 저가화 등을 위해 다양한 연구들이 수행되고 있다. 일반적으로 화재에 의해 발생되는 열, 연기 및 화염을 감지하는 센서들을 활용한 연구가 활발하게 진행되고 있으나 오염에 의한 오작동 및 감지 범위의 제한 등의 기술적 한계가 존재한다(1,2). 이러한 화재감지기술을 개선하고자 컴퓨터 비전 분야 기술의 발전으로 화재 이미지의 특성을 활용하는 화재감지기술에 관한 연구가 활발하게 진행되고 있다(3).
컴퓨터 비전 분야에서 이미지의 색상은 화재를 감지하는 중요 요소로서 RGB, YCbCr 등을 활용한 공간상의 색상 차이로 인하여 화염 혹은 연기를 감지, 광 흐름을 이용한 연기 이동 특성을 고려한 감지, 연기에 의해 흐릿해지는 이미지를 연출하는 웨이블릿(wavelet)을 활용한 감지, 화염이나 연기의 영역 변화를 고려한 감지 등 다양한 연구가 이루어지고 있으나 일반화된 화재 감지 성능을 갖는 데는 한계가 존재하였다. 최근에는 이미지의 공간적 특징을 추출하여 높은 예측 성능을 갖는 합성곱 신경망(convolutional neural network, CNN)이 이용되고 있으며 CNN 모델을 이용한 화재 예측 성능 향상에 관한 많은 연구들이 수행되고 있다(4-7).
Kim과 Kim(8)은 다중 분류가 가능한 CNN모델을 이용하여 화재에서 발생되는 화염과 연기를 동시 예측하여 화재 감지를 알리면 화염 혹은 연기의 위치를 Gad-CAM을 활용하여 시각화하는 화재감지시스템을 제안하였다. CNN 모델 들인 Inception V3, Xception, Inception ResNet V2의 성능을 비교한 결과 Inception ResNet V2 모델이 가장 좋은 예측 정확도를 보임을 확인하였다. 제안된 화재감지시스템을 통해 화염 및 연기에 대한 예측정확도를 각각 약 98.7%와 95.8%를 얻었다. Huang 등(9)은 기존 CNN 모델의 예측 정확성을 개선하기 위하여 이미지의 스펙트럴 특징을 추출하는 2D Haar 변환을 적용한 새로운 Wavelet-CNN 기법을 제안하였으며 기존 모델인 ResNet50과 MobileNet v2와 함께 비교 검토하였다. 새로운 Wavelet을 적용한 기법이 계산이 빠르게 이루어지면서 화재 검출 정확도가 높아 실용적임을 확인하였다. Majid 등(10)은 CNN 모델의 알고리즘을 이용하여 화재를 감지하고 Grad-CAM 알고리즘을 이용하여 화재의 위치를 시각화하는 방법을 제안하고 VGG16, GoogleNet V3, ResNet 50, EfficientNet B0등 4가지 모델의 성능을 비교 분석하였다. 그 결과 EfficientNetB0가 가장 예측 성능이 우수하였으며 실화재 이미지 데이터를 활용하여 정확도 95.4%와 재현율 97.6%의 우수한 모델 성능을 보임을 확인하였다. Sharma 등(11)은 학습하는 화재 이미지 데이터 셋과 실제 화재의 이미지와의 차이에 의해서 발생되는 예측 성능 저하를 해결하기 위해서 기존의 CNN 모델의 미세조정을 통한 계층 깊이를 늘리고 구분하기 어려운 비 화재 이미지가 상대적으로 많이 포함된 데이터 셋을 활용한 학습을 제안하여 보다 좋은 예측 성능을 보임을 확인하였다. Li와 Zhao(12)는 기존 화재감지 알고리즘의 낮은 예측정확도와 늦은 계산시간을 개선하기 위하여 객체 검출 CNN 모델들을 이용한 방법을 제안하였으며 Faster-RCNN, R-FCN, SSD와 YOLO v3에 대한 성능비교평가를 수행하였다. 결과로서 YOLO v3의 화재감지 성능이 가장 우수하고 높은 강건성과 빠른 검출 속도를 가지고 있어 실제 화재감지에 가장 적합하다고 판단하였다.
이와 같이 기존의 CNN 알고리즘을 기반한 화재 감지 연구들은 다양한 방법을 통한 화재 예측 성능 개선에 관한 연구가 주를 이루고 있다. 고성능의 딥러닝 분류모델은 학습과정에서 높은 연산성능이 요구되며 추론과정에서도 많은 연산시간 및 저장 공간 등이 요구된다. 이러한 고성능 딥러닝 분류모델의 필요 조건은 최근 엣지 컴퓨팅(edge computing)(13,14) 기반의 지능형 예측기술에는 적절하지 않다. 따라서 본 연구에서는 화재 안전 향상을 위한 엣지 컴퓨팅 기반 화재감지시스템에 적용 가능한 대표 CNN모델들인 MobileNetV2, ResNet101, EfficientNetB0를 이용하여 화재 및 비 화재 분류와 함께 추론시간 및 모델 용량 측면에서의 성능을 비교 분석하였다. 더하여 화재와 유사한 비 화재 이미지 특성에 대해 추가 학습을 통해 경량화에 적합한 모델의 화재 예측 성능 개선 가능성을 검토하였다.
2. 연구 방법
본 연구에서는 높은 예측 성능을 갖는 경량화 된 분류 모델을 검토하기 위하여 CNN 기반의 화재 이미지 분류 모델들의 화재 예측 성능을 비교 분석하였다. Figure 1은 화재 이미지 분류 및 평가 수행 절차를 보여준다. 본 연구에서 사용한 이미지 데이터 셋은 총 8,000장의 이미지들로서 화재 이미지와 비 화재 이미지로 구성되었다. 화재 이미지는 화염과 연기 이미지로 구성되며 비 화재 이미지는 다양한 환경 조건에서의 건물, 거리, 실내 공간, 산 등의 일상 이미지들로 구성하였으며 Figure 2에 대표 이미지를 나타냈다. 분류 모델의 화재 예측 성능 비교 분석을 위해서 화염 이미지, 연기 이미지, 비 화재 이미지를 각각 1,600장으로 구성하여 총 4,800장의 이미지 데이터를 이용하였다. 각 이미지 데이터는 6:1:1의 비율로 학습을 위한 학습 데이터(training), 학습 단계에서 모델의 예측 성능을 평가하는 검증 데이터(validation), 최종 분류 모델의 예측 성능을 평가하기 위한 시험 데이터(test)로 구분하였다. 본 연구에서는 이미 훈련된 MobileNetV2, ResNet101, EfficientNetB0 분류 모델을 호출하고 준비된 화재 및 비 화재 학습 데이터를 이용하여 전이 학습을 진행하였으며 검증 데이터를 통해 최상의 예측 성능을 갖는 모델을 선정하였다. 선정된 분류 모델은 준비된 시험 데이터를 이용하여 화재 예측 성능 평가 및 비교 분석을 진행하였다. 비교 분석 후 선정된 경량 모델의 성능향상을 위해 비 화재 이미지 중 화재 이미지와 유사한 연무 이미지와 빛 이미지를 클래스로 추가하여 학습을 진행하였다. 본 성능평가에는 총 8,000장의 이미지 데이터를 이용하였으며 학습 및 성능평가를 위한 수행 절차는 Figure 1과 같이 진행하였다.
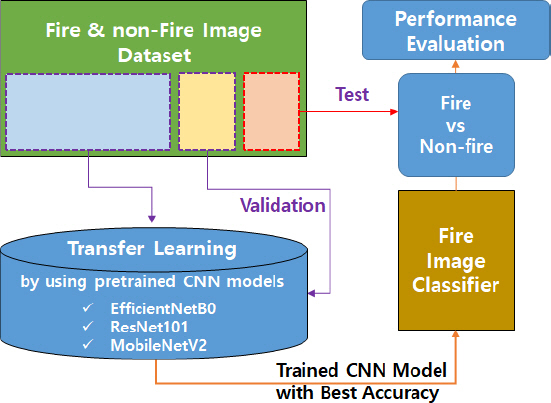
Procedure of fire image classification.

Representative images for image dataset.
머신러닝 이미지 분류 모델은 공간에 따른 픽셀 간 관계를 고려하지 못하기 때문에 공간정보를 반영한 이미지 특징 추출이 가능한 CNN이 컴퓨터 비전 분야에서 가장 많이 사용하는 딥러닝 알고리즘이다. Figure 3과 같이 CNN은 입출력 계층과 그 사이의 여러 은닉 계층으로 구성된다. CNN은 이미지의 공간정보를 활성화 시키는 합성곱 층(convolution layer)과 특성 맵의 차원을 줄여 결국은 학습의 파라미터 수를 줄임으로써 학습 속도를 향상시키기 위한 풀링 층(pooling layer)를 통해서 이미지의 주요 특징들을 검출할 수 있도록 학습한다. 분류계층에서 완전 연결 층(fully connected layer)을 통해서 이미지에 따른 각 클래스를 확률적으로 분류하여 최종 분류를 출력한다. CNN은 망의 깊이(depth) 증가, 채널의 폭(width) 증가, 입력 이미지의 해상도 개선 등의 방법으로 모델의 성능을 향상 시킨다. 하지만 망의 깊이가 깊어질수록 기울기 소실 등의 문제로 학습이 어려워져 망의 깊이를 증가시키는데 한계가 존재한다. 이러한 문제를 해결하기 위하여 ResNet은 잔차 학습(residual learning)을 적용하여 망의 깊이를 더욱 증가시키는 깊이 스케일링(depth scaling)을 통해서 분류 모델의 성능을 향상시켰다. 깊이의 증가에 따라서 성능은 향상되지만 모델은 무거워지는 단점이 있으며 본 연구에서는 화재 이미지 분류에 많이 이용되고 있는 ResNet101을 선정하였다. EfficientNet의 경우 성능 향상을 위한 망의 깊이, 채널의 폭, 이미지의 해상도의 최적 조합을 도출하는 복합 스케일링(compound scaling)방법을 적용하고 있다. 이를 통해 기존 보다 적은 파라미터 수를 통해 향상된 성능을 도출할 수 있도록 하였으며 본 연구에서는 EfficientNet 모델 중 상대적으로 경량모델인 EfficientNetB0를 선정하였다. MobileNet은 공간과 채널을 모두 고려하는 기존 합성곱(convolution) 방식을 깊이별 합성곱(depthwise convolution)와 점별 합성곱(pointwise convolution)으로 분리하는 방식으로 파라미터 수 및 연산량 감소시킨 경량모델이다. 본 연구에서는 내부 채널을 확장하고 압축하는 형태의 역 잔차 블록(inverted residual block)을 추가하여 MobileNet보다 더욱 경량화되면서 성능이 향상된 MobileNetV2를 선정하였다. 특정 분야의 이미지 분류를 위해 잘 훈련된 CNN모델을 만들기 위해서는 다량의 이미지 데이터가 필요하고 데이터를 정리하고 학습하는데 많은 시간이 소요된다. 이러한 부분을 개선하고자 특정 분야 다량의 이미지 데이터를 활용하여 잘 훈련된 분류 모델을 호출하여 새로운 분류를 위한 학습을 진행하는 전이 학습(transfer learning)을 이용한다. 이러한 전이 학습은 적은 학습데이터로도 효과적으로 학습하고 높은 정확도를 만들 수 있다는 장점을 가지고 있어 유용한 방법으로서 널리 이용되고 있다. 본 연구에서는 전처리 과정으로 224 × 224 크기의 RGB의 입력 이미지 데이터 셋을 이용하여 기 학습된 3가지 분류모델들(ResNet101, EfficientNetB0, MobileNetV2)을 호출하여 전이학습을 진행하였으며 최적의 예측 성능을 갖는 모델을 도출하여 화재 예측 성능을 평가하였다.

3. 연구 결과 및 고찰
화재 예측 성능을 평가하기 위해서 혼동 행렬(confusion matrix)을 이용하여 각 분류 모델의 상세 예측 특성을 확인하고 분석하였으며 정량적 성능평가를 위해서 정밀도, 재현율, 정확도, F1-score 등의 평가지표를 이용하였다. 화재 및 비 화재 분류에서 도출 가능한 4가지 예측을 Table 1에 나타내었다. 화재 감지를 기준으로 화재(positive)와 비 화재(negative)를 분류하는 경우 만약 실제 비 화재 이미지를 비 화재로 예측하면 TN, 실제 화재 이미지를 화재로 예측하면 TP로 나타낸다. FN의 경우 실제 화재 이미지를 비 화재로 예측하는 경우이며 FP는 실제 비 화재 이미지를 화재로 잘못 예측한 경우를 나타낸다. 이러한 예측 결과를 이용하여 화재라고 예측한 것 중 실제 화재인 비율을 나타내는 정밀도(precision), 실제 화재 중 화재라고 예측한 비율을 나타내는 재현율(recall), 전체 예측 건 수 대비 정확하게 예측한 건수의 비율을 나타내는 정확도(accuracy), 재현율과 정밀도의 조화평균을 나타내는 F1-score를 이용하여 분석하였으며 아래의 식(1)에서 식(4)에 의해서 각각 계산되었다.

Possible Outputs of Image Classification
분류 모델의 화재 예측 성능을 비교 분석하기 위해서 화염 이미지, 연기 이미지, 비 화재 이미지 등 3가지의 이미지 클래스를 통해 MobileNetV2 모델을 학습하고 예측 성능을 평가한 결과를 Table 2의 혼동 행렬로 나타냈다. 또한 분류 모델의 상세 예측 특성을 파악하기 위해서 이미지 별 예측 결과를 분석하였으며 잘못 예측한 대표 이미지들을 Figure 4에 나타내었다. 분류 모델이 화염 이미지라고 예측한 것 중에 실제 화염 이미지인 비율을 나타내는 정밀도는 약 93.8%이며 실제 화염 이미지를 화염 이미지로 예측한 비율인 재현율은 약 97.5%로 나타났다. 대부분 한 이미지에 화염과 연기가 혼재되어 있어 화염 이미지를 연기로 잘못 예측하였으며 뿌옇게 보이는 화염 이미지가 비 화재 이미지로 잘못 예측하는 경우도 있었다. 더하여 비 화재 이미지 중 화염과 유사한 간판, 가로등, 차량, 태양 등의 빛이 포함된 이미지를 화염이라고 예측한 경우가 다수 존재하였으며 이러한 이유로 상대적으로 정밀도가 낮게 나타났다. 연기 이미지 예측의 경우 정밀도와 재현율이 각각 약 82.3%와 약 97.5%로 나타났다. 실제 연기 이미지에 대해서는 우수한 예측 성능을 보이고 있으나 연무와 같이 연기와 유사한 특징을 갖는 비 화재 이미지를 연기 이미지로 예측하는 경우가 많아서 정밀도가 상대적으로 낮게 나타난 것으로 판단된다. 비 화재 이미지 예측의 경우 정밀도와 재현율은 각각 약 98.7%와 약 76.5%로 재현율이 상대적으로 낮게 나타났다. 분류 모델이 비 화재 이미지라고 예측한 것 중에 실제 비 화재 이미지일 확률은 높았으나 실제 이미지를 보고 비 화재 이미지로 예측하는 성능은 낮은 것으로 확인되었으며 약 4:1 비율로 연기와 화염으로 잘못 예측하였다. 먼저 화염이라고 잘못 예측한 경우 간판, 가로등, 차량, 태양 등의 빛이 포함된 이미지를 잘못 인식하는 경우이며 연기로 잘못 예측한 경우는 기상 상태에 의해 여러 장소에서 발생될 수 있는 연무를 연기로 잘못 예측하는 것이었다. MobileNetV2의 화재 및 비 화재 분류 성능을 개선하기 위해서는 화염 및 연기와 유사한 이미지 특징을 갖고 있는 사물 혹은 현상에 대한 이미지에 대해서 추가적인 학습이 필요할 것으로 판단되며 명암, 대조, 흐릿함 등 다양한 이미지 효과를 고려한 모델 학습이 고려되어야 할 것으로 판단된다.

Confusion Matrix for MobileNetV2

Incorrect prediction cases of MobileNetV2.
ResNet101과 EfficientNetB0 모델에 대해서 MobileNetV2와 동일한 방법으로 학습, 성능평가 및 분석을 수행하였으며 Figure 5에 각 모델의 상세 예측 결과 분석을 통해서 잘못 예측한 예시를 나타냈다. ResNet101 모델에서 화염 이미지 예측의 경우 정밀도와 재현율은 각각 약 96.5%와 약 96.0%로 우수한 예측 성능을 보였으며 일부 흐리거나 밝게 촬영 된 화염 이미지를 비 화재 이미지로 잘못 예측하고 있는 것으로 나타났다. 연기 이미지 예측의 경우 정밀도와 재현율이 각각 약 91.5%와 약 97.5%로 나타났다. 실제 연기 이미지에 대해서는 우수한 예측 성능을 보이고 있으며 연무와 같이 연기와 유사한 특징을 갖는 비 화재 이미지를 연기 이미지로 예측하는 경우가 많아서 정밀도는 상대적으로 낮았으나 MobileNetV2 보다는 향상된 성능을 나타냈다. 비 화재 이미지 예측의 경우 정밀도와 재현율은 각각 약 95.2%와 약 89.5%로 재현율이 상대적으로 낮은 것으로 확인되었다. 분류 모델이 비 화재 이미지를 연기와 화염으로 잘못 예측하였으며 MobileNetV2와 유사한 예측 경향을 보였으나 잘못 예측한 수는 상대적으로 적은 것으로 나타났다. EfficientNetB0 모델에서 화염 이미지 예측의 경우 정밀도와 재현율은 각각 약 93.4%와 약 99.0%로 우수한 예측 성능을 보였으며 비 화재 이미지 중 화염과 유사한 특성을 갖는 빛이 포함된 이미지를 화염이라고 예측한 경우가 있어 상대적으로 정밀도가 낮게 나왔다. 연기 이미지 예측의 경우 정밀도와 재현율이 각각 약 91.6%와 약 98.5%로 나타났다. 연무를 포함하는 비 화재 이미지를 연기 이미지로 예측하는 경우가 많아서 정밀도가 상대적으로 낮게 나타났으나 MobileNetV2에 비해서는 향상된 성능을 보이고 있다. 비 화재 이미지 예측의 경우 정밀도와 재현율은 각각 약 99.4%와 약 86.0%로 정밀도는 매우 높으나 재현율이 상대적으로 낮게 나타났다. 분류 모델이 비 화재 이미지를 연기와 화염으로 잘못 예측하였으며 정량적으로 MobileNetV2에 비해서는 잘못 예측한 경우의 수가 적은 것으로 나타났다. 결과적으로 EfficientNetB0와 ResNet101은 MobileNetV2에 비해서 상대적으로 우수한 화재 예측 성능을 보였으나 화재 예측 경향은 유사한 것으로 판단된다. 즉 잘못 예측하고 있는 화염 및 연기와 유사한 이미지 특징을 갖는 사물 혹은 현상에 대한 추가적인 학습으로 EfficientNetB0와 ResNet101 모델의 예측 성능을 향상시킬 수 있을 것으로 판단된다.

Incorrect prediction cases: (a)~(d) for ResNet101, (e)~(f) for EfficientNetB0.
분류 모델들이 화재(화염 및 연기)와 비 화재를 분류 예측할 때의 예측 성능을 비교하기 위해서 Figure 6에 성능평가지표에 대한 결과를 표시하였다. 성능비교결과 EfficientNetB0, ResNet101, MobileNetV2 모델이 각각 95.2%, 95.0%, 91.8%의 화재 예측 정확도를 가지며 세 분류 모델 중 EfficientNetB0가 가장 우수한 예측 성능, MobileNetV2가 가장 낮은 예측 성능을 갖는 분류모델로 확인되었다. 모든 분류모델들은 화재 및 비 화재를 분류하는 정밀도가 재현율보다 높게 나타났으며 비 화재 이미지 중 다양한 일상에서의 빛과 연무가 포함 된 이미지를 화재로 인식하기 때문에 나타난 결과로 판단된다. 따라서 분류 모델의 화재 및 비 화재 예측이 맞을 확률은 높으나 화재 및 비 화재로 구분하는 예측 성능은 상대적으로 낮은 것으로 판단된다. 정밀도와 재현율의 조화 평균인 F1-score는 EfficientNetB0, ResNet101, MobileNetV2 모델이 각각 94.6%, 94.3%, 90.9%를 갖는 것으로 나타났다. 결과적으로 화재 및 비 화재 분류 예측 성능은 EfficientNetB0, ResNet101, MobileNetV2 순서로 우수한 것으로 확인되었다. 각 모델의 예측 성능의 차이는 있었으나 성능 저하 원인 유사하여 화재와 유사한 특징을 갖는 비 화재 이미지를 잘 인식 할 수 있도록 학습 등의 다양한 방법을 통하여 예측 성능을 향상 시킬 수 있을 것으로 판단된다.
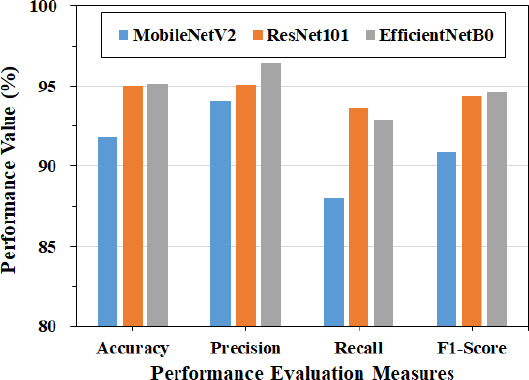
Comparison on prediction performance of fire image classification models.
화재 안전 향상을 위한 엣지 컴퓨팅(edge computing) 기반 화재 감지로의 적용성 측면에서 예측 성능과 더불어 적용 모델의 용량, 화재 및 비 화재 추론시간 등이 중요한 요소이다. 따라서 Figure 7에 화재 및 비 화재 분류를 위한 최종 모델들의 모델 크기를 나타냈다. EfficientNetB0, ResNet101, MobileNetV2의 모델 크기는 각각 19.2 MB, 175.2 MB, 12.1 MB로서 MobileNetV2 모델이 가장 적은 용량을 갖는 것으로 나타났다. 더하여 분류 모델의 예측 성능평가를 위한 전체 시험 데이터 셋의 이미지들을 분류하는데 소요되는 평균 추론시간을 측정하여 Figure 8에 나타냈다. 측정 결과 EfficientNetB0, ResNet101, MobileNetV2의 평균 추론시간은 각각 18.6 s, 22.6 s, 15.4 s로서 MobileNetV2 모델이 가장 빠르게 화재 및 비 화재를 분류하는 것으로 나타났다. 따라서 검토한 세 가지 분류모델 중 엣지 컴퓨팅 기반 화재 감지시스템 구현을 위해서 필수적인 작은 모델 크기 및 짧은 추론시간을 갖는 MobileNetV2가 가장 우수한 경량모델이라고 판단된다.

Comparison on model size of fire image classification models.

Comparison on inference time of fire image classification models.
분류 모델들에 대한 성능 비교 분석을 통해서 경량화 측면에서 적은 저장 공간과 연산량을 필요로 하는 MobileNetV2가 우수한 것으로 판단되었으나 화재 예측 정확도 측면에서는 EfficientNetB0에 비해서 낮아 비 화재보 발생 빈도가 상대적으로 높을 것으로 판단된다. 따라서 본 연구에서는 MobileNetV2 모델에 화재를 나타내는 화염 및 연기와 유사한 특징을 갖는 비 화재 이미지인 빛과 연무에 관한 데이터 셋을 준비하여 화염, 연기, 빛, 연무, 비 화재(빛, 연무 이미지 제외)로 분류하여 학습을 진행하고 화재 및 비 화재 분류 성능의 개선여부를 평가하였다. 성능 평가 결과 예측 정확도가 98.7%로 향상됨을 확인하였으며 기존에 예측 오류가 많았던 비 화재 이미지 중 화염이나 연기와 혼동이 발생될 수 있는 간판, 가로등, 태양 등의 빛이 포함된 이미지들과 다양한 공간에서 생성되는 연무를 포함한 이미지들을 비 화재로 예측이 현저하게 증가하면서 분류성능이 향상된 것으로 확인하였다. 분류 모델의 상세 예측 결과를 분석하여 잘못 예측한 이미지들에 대한 예시 사진들을 Figure 9에 나타내었다. 이미지 수집 환경에 따라서 이미지가 흐리거나 명암, 색조 등의 변화가 있는 경우 화염과 빛 이미지 간의 분류 오류, 연기를 비 화재로 예측하는 등의 오류가 여전히 발생되고 있는 것으로 확인되었다. 따라서 보다 정확한 화재 및 비 화재 예측 성능에 대한 분석을 위해서 다양한 화재 발생 시나리오에서의 실제 데이터를 이용한 성능평가가 지속적으로 필요하며 객체 인식 등을 통한 이미지 특징 변화에 기인한 예측 성능 개선 등이 이루어져야 할 것으로 판단된다.

Incorrect prediction cases of MobileNetV2 enhanced.
4. 결 론
본 연구에서는 화재 안전 향상을 위한 엣지 컴퓨팅(edge computing) 기반 화재감지 및 경보시스템에 적용 가능한 CNN기반의 이미지 분류 모델들인 MobileNetV2, ResNet101, EfficientNetB0를 이용하여 화재 및 비 화재 분류 해석을 수행하였다. 분류 모델들의 화재 및 비 화재 분류 예측, 모델 용량, 추론시간 등의 성능에 대한 비교 분석을 통하여 아래와 같은 결과를 도출하였다.
- 화재 및 비 화재 예측 정확도는 EfficientNetB0, ResNet101, MobileNetV2 모델이 각각 95.2%, 95.0%, 91.8%로 나타났으며 EfficientNetB0가 가장 우수한 성능을 보였다. 상세 예측 특성 분석 결과, 화재와 유사한 특징을 갖는 비 화재 이미지인 빛, 연무와 관련된 이미지들에 대한 잘못된 예측이 예측 성능 저하의 원인으로 판단되었다.
- 엣지 컴퓨팅 적용성을 위한 경량화 측면에서 비교 분석한 결과 MobileNetV2, EfficientNetB0, ResNet101순으로 적은 모델 용량, 빠른 추론시간을 갖는 것으로 확인되었다.
- 경량모델인 MobileNetV2를 이용하여 화재와 유사한 특징을 갖는 비 화재 이미지인 빛과 연무에 대한 이미지 특성을 추가 학습한 결과 화재 및 비 화재 예측 정확도가 98.7%로 향상됨을 확인하였다.
추후 화재감지시스템 적용을 위해서는 경량 이미지 분류 모델의 강건성 향상이 필수적이다. 따라서 다양한 화재 발생 시나리오 기반 성능평가, 객체 인식 등을 통한 화재 이미지 특징 변화에 기인한 화재 예측 성능 개선, 화재 감지 센서와의 연계를 통한 예측 성능 개선에 관한 연구들을 진행할 예정이다. 더하여 실제 화재환경에서 CNN모델을 탑재한 엣지 컴퓨팅 하드웨어기반 화재 감지를 통해 모델의 적용성 평가를 수행할 예정이다.
후 기
본 연구는 국토교통부/국토교통과학기술진흥원의 지원(RS-2022-00156237)으로 수행되었으며 이에 관계제위께 감사드립니다.