사회지표를 활용한 다층퍼셉트론 기반 화재발생예측
Prediction of Fire Occurrences Based on Multi-layer Perceptron Using Social Indicators
Article information
Abstract
요 약
도시의 사회경제적⋅인구통계학적 요인이 화재 발생에 미치는 영향을 분석하고 각 요인에 따른 화재 발생을 예측하기 위해, 본 논문에서는 ‘한국의 사회지표’와 화재 발생의 상관관계를 분석하고, 이를 바탕으로 다층퍼셉트론(multi layer perceptron, MLP) 기반 화재 예측 모델을 구축하고자 한다. 이를 위해 2015년부터 2022년까지의 시⋅군⋅구별 사회지표와 화재 발생 건수 데이터를 수집하고, 사회지표와 화재 발생의 상관성을 분석하고, 분석결과를 바탕으로 15개 요인(Model 1)과 5개 요인(Model 2)을 활용하여 화재를 예측할 수 있는 두 개의 모델을 구축하였다. 구축된 모델의 절대 백분율 오차는 각각 26.37% (Model 1), 30.92% (Model 2)로 나타나, 사회지표를 활용한 다층퍼셉트론 기반 화재 예측 모델의 활용 가능성을 확인하였다.
Trans Abstract
ABSTRACT
To analyze the impact of urban socioeconomic and demographic factors on fire occurrences and predict fire occurrences according to each factor, this study analyzed the correlation between “Korean social indicators” and fire occurrences. Based on this, a fire prediction model was built based on multi-layer perceptron (MLP). For this purpose, data on social indicators and the number of fires by city, county, and district from 2015 to 2022 were collected, and the correlation between social indicators and fire occurrences were analyzed. Based on the correlation analysis results, two models were built to predict fires using 15 factors (Model 1) and 5 factors (Model 2). The mean absolute percentage error of the models were 26.37% (Model 1) and 30.92% (Model 2), confirming the usability of the fire prediction model based on the multi-layer perceptron using social indicators.
1. 서 론
화재는 경제적 손실, 인적 피해, 그리고 지역사회에 미치는 영향 등으로 인해 사회적으로 심각한 문제로 대두되고 있으며(1), 사회⋅경제발전과 건축물의 고층화와 복합화 및 다양한 에너지원을 사용하는 시설의 증가에 따라 화재로 인한 재산 피해는 증가하고 있다(2). 도시화재는 도시의 사회경제적, 인구통계학적, 건축적 요인(3)과 같은 다양한 요인에 의해 발생하기 때문에 이러한 요인들을 복합적으로 고려하여 화재의 발생을 예측하고 예방⋅대비하는 것이 중요하다.
이에 본 연구에서는 사회상태의 종합적 측정, 사회변화 예측 및 사회정책의 성과 측정을 위해 투입⋅과정⋅성과 지표를 모두 다루는 포괄적 지표인 ‘한국의 사회지표’와 화재 발생의 상관관계를 분석하고 이를 바탕으로 다층퍼셉트론(multi layer perceptron, MLP) 기반 화재 예측 모델을 구축하여 도시의 화재 발생 건수를 예측하고자 한다.
이를 위해 2015년부터 2022년까지의 시⋅군⋅구별 화재 데이터와 사회지표를 수집하고 분류하였으며, 화재 발생 건수와 사회지표 간의 상관성 분석을 바탕으로 화재발생예측 모델의 입력변수를 선정하였다. 선정된 입력변수를 활용하여 다중퍼셉트론(MLP) 기반 화재 예측 모델을 구축하였으며, 최종적으로 구축된 화재 예측 모델의 성능검증을 통해 모델의 활용 가능성을 제시한다.
2. 이론적 고찰
2.1 한국의 사회지표의 개요
‘한국의 사회지표’는 한국의 사회상을 종합적⋅집약적으로 살펴, 국민의 삶과 관련한 전반적인 경제⋅사회 변화를 쉽게 양적⋅질적으로 파악하고, 현재 사회상태를 종합적⋅체계적⋅균형적으로 알 수 있게 하는 정보의 역할 수행하며, 사회구조 변화와 관심 분야를 파악하여 각종 정책의 계획수립이나 정책 결정 및 효과 측정에 유용한 기초자료를 제공하는 지표이다(4).
‘한국의 사회지표’는 4가지 부문(개인, 사회, 경제, 환경), 12개 영역(‘인구’, ‘가구⋅가족’, ‘건강’, ‘교육⋅훈련’, ‘노동’, ‘소득⋅소비⋅자산’, ‘여가’, ‘주거’, ‘환경’, ‘범죄와 안전’, ‘사회통합’, ‘주관적 웰빙’)으로 구분되며, 12개의 영역 내 270개의 지표로 구성된다.
2.2 상관성 분석의 정의와 방법
상관성 분석은 두 변수 간의 관련성을 파악하고 측정하는 통계적 방법으로, 주어진 데이터에서 변수 간의 상호 연관성을 이해하고, 그 관계의 강도와 방향을 파악하기 위한 통계적 방법이다. 가장 일반적인 상관성 분석 방법의 하나는 피어슨 상관계수를 사용하는 것으로, 피어슨 상관계수는 두 변수 간의 선형 관계의 강도를 측정하는 지표로, -1에서 1까지의 값을 가진다. 이때 1에 가까울수록 양의 선형 관계를, -1에 가까울수록 음의 선형 관계를, 0에 가까울수록 선형 관계가 없음을 나타낸다.
일반적으로 피어슨 상관계수(r)의 절댓값이 0.7보다 크면 매우 강한 선형관계로 해석되며, r의 절댓값이 0.3보다 크고 0.7보다 작을 때 강한 상관관계, 0.3 보다 작을 때 약한 상관관계를 가지는 것으로 해석된다. 또한 상관성 분석결과에 따른 p-value (p값)는 상관계수의 유의수준을 의미하며, 0.05보다 작은 p값을 가질 때 상관계수가 통계적으로 유의미하다는 것을 의미한다.
2.3 화재 예측을 위한 신경망 모델
신경망은 인간 두뇌의 구조를 모방하여 정보처리 및 예측에 활용되는 계산모델로, 다중퍼셉트론(MLP), 합성곱 신경망(convolutional neural network, CNN), 순환신경망(recurrent neural network, RNN) 등이 대표적이며, 이러한 모델들은 변수 간의 관계를 탐구하고 처리하는 데 활용되고 있다. 대표모델의 특징을 살펴보면, MLP는 복잡한 관계를 처리하고 다차원 데이터의 예측 및 분류에 적합하며, CNN은 이미지와 공간 데이터 처리에 탁월하며 복잡한 특징을 추출하는 데 우수하다. RNN은 시간적 관련성이 있는 사회적 지표 데이터를 다루는 데 효과적이다. 이러한 모델들은 데이터의 유연한 특성 추출과 패턴 인식을 통해 변수 간의 잠재적 관련성을 깊게 파악할 수 있는 장점이 있다.
신경망 모델을 활용한 화재와 관련된 선행연구를 살펴보면, MLP 모델을 기반으로 17개의 변수(지형 요인, 인류학 및 환경 요인, 기후 요인 및 식생 요인)를 사용하고 산불 감수성 모델을 개발하거나(5), CNN 기반 이미지 분류 모델을 이용하여 화재 감지 시스템의 화재 예측 성능 관련 연구 등이 수행되어왔다(6,7).
본 연구의 목적은 사회지표를 활용하여 화재 발생 건수를 예측하는 모델을 제시하는 것으로, 대표모델 중 다양한 변수와의 관계를 탐구하고 분석하는데 가장 적합한 모델인 다중퍼셉트론 모델을 활용하고자 한다. MLP는 다층 구조를 통해 복잡한 비선형 관계를 포착할 수 있으므로, 사회지표와 같은 다양한 요소들을 반영하기에 유용하다. 또한, MLP의 다층 은닉층은 데이터의 추상적인 특성을 계층적으로 학습하여 데이터 패턴을 잘 이해할 수 있고, 다양한 종류의 데이터에 적응할 수 있는 유연성을 가지고 있어서, 사회지표를 활용한 화재 발생 건수를 예측에 가장 적합한 모델이다.
2.4 다중퍼셉트론의 정의와 방법
다층퍼셉트론은 인공 신경망의 한 유형으로 여러 개의 은닉층을 포함하는 인공 신경망 구조이다(Figure 1).
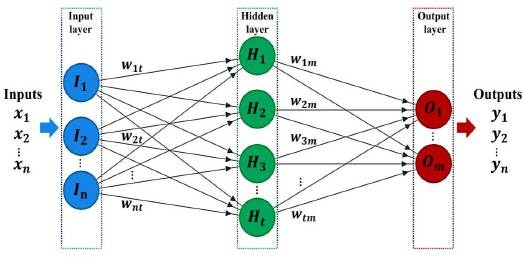
MLP model prediction.
입력층(input layer)에서 시작해 은닉층(hidden layer)을 거쳐 출력층(output layer)에서 결과를 내보낸다. 각 층으로 구성된 비선형 함수 근사를 수행하고 복잡한 패턴을 학습하는 데 사용된다. 각각의 층은 처리 요소인 노드(node)들로 구성되고 이전 층에서 오는 입력과 가중치(weight)를 곱한 후 활성화 함수를 통과한다. 가중치가 부여된 선으로 연결되어 각 노드는 이전 단계의 출력값을 산출한다. 이는 비선형성을 학습하고 데이터 패턴을 이해하여 역전파로 가중치를 조정해 오차를 최소화한다. 이러한 MLP는 패턴 인식, 예측, 분류 등의 다양한 작업에 활용되며 이를 통해 네트워크의 계산을 나타내거나 학습 알고리즘에 적용할 수 있으며, 다음의 식(1)과 같이 표현된다:
여기서, y는 뉴런의 출력을 나타낸다. ∅는 활성화 함수로, 입력에 비선형성을 부여하며 주로 rectified linear activation (ReLU), sigmoid, tanh 등이 사용된다. Xi 는 입력의 i 번째 특성(feature)을 나타낸다. wi는 해당 특성에 대한 가중치이다. b는 편향(bias)이며 W는 가중치의 벡터를 나타내며, X는 입력 특성의 벡터이다.
앞서 설명한 바와 같이, MLP 모델은 주로 기본적인 분류 및 회귀 문제에 활용되며, 충분한 수의 뉴런과 적절한 훈련데이터가 있으면 거의 모든 종류의 함수를 정확하게 근사할 수 있는 뛰어난 비선형 모델링 능력을 보여주기 때문에, 본 논문에서는 사회지표를 활용한 화재 발생 건수 예측모델로 MLP 모델을 선정하였다(8,9).
3. 사회지표와 화재 발생 건수의 상관성 분석
3.1 데이터 수집 및 분류
화재 발생 건수 데이터의 수집은 소방청 국가화재정보시스템(https://nfds.go.kr)을 통해 2015∼2022년까지의 국내 252개 시⋅군⋅구 지역의 데이터가 수집되었다. 수집된 252개 지역의 데이터 중 결측값이 있는 3개의 지역의 데이터를 제외한 249개 지역의 총 1,992개 화재 발생 건수(건) 데이터가 분석에 활용되었다.
사회지표 데이터의 수집은 Figure 2와 같이 데이터 수집, 데이터 분류와 데이터 정제의 3개의 단계로 구분된다. 우선 첫 번째 데이터 수집의 단계는 통계청 국가통계포털(https://kosis.kr)을 통해 한국의 국가지표로 제공되는 270개의 사회지표 데이터를 수집하였다.

Data collection and classification process.
이후 데이터 분류의 단계에서 데이터 분류 작업을 통해 수집된 데이터 중 시⋅군⋅구 단위로 분류할 수 있는 24개 지표의 데이터를 추출하였다. 마지막으로 데이터 정제의 단계를 통해 화재 발생 건수 데이터의 수집 기간인 2015년부터 2022년까지의 데이터 중 결측값이 있는 데이터를 제거하는 과정을 거쳐 최종적으로 15개 지표 22개 요인을 포함하는 데이터셋을 구축하였다(Table 1). 11번 가족 형태별 가구 구성의 경우는 가족 구성 형태에 따라 화재에 미치는 영향을 세부적으로 분석하기 위해, 데이터 정제 과정을 거쳐 8개의 세부 요인(1인 가구의 비율, 1인 가구의 수, 1세대 가구의 비율, 1세대 가구의 수, 2세대 가구의 비율, 2세대 가구의 수, 3세대 가구의 비율, 3세대 가구의 수)으로 세분화하였다.
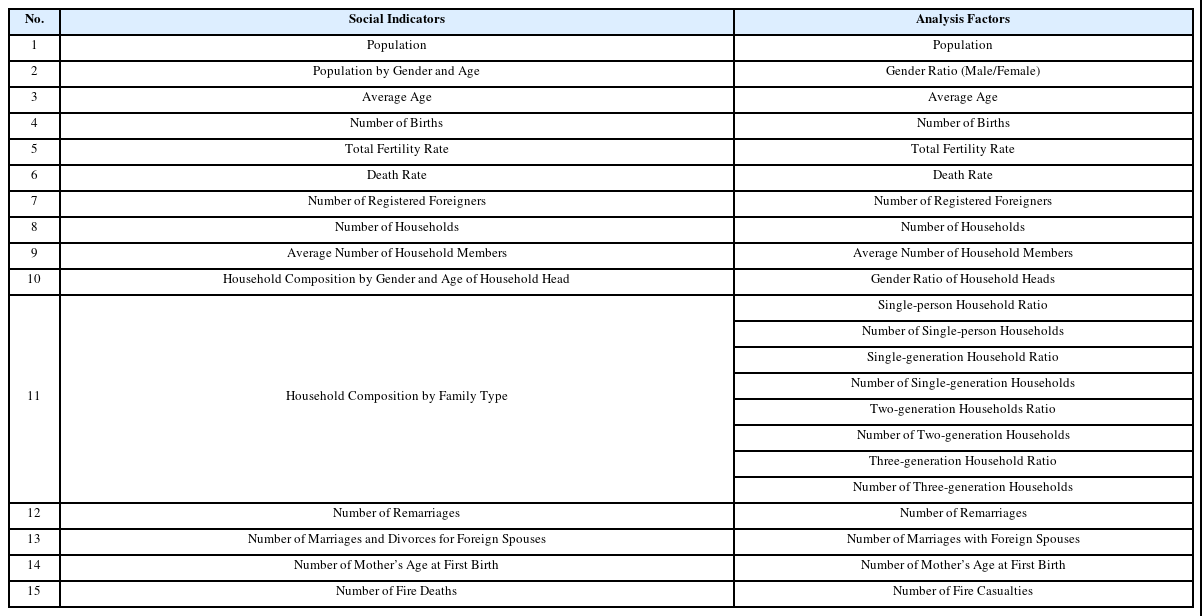
Social Indicators and Analysis Factors
3.2 상관성 분석 결과
화재 발생 건수 데이터와 사회지표에 관한 22개 요인의 상관관계 분석 결과는 Table 2와 같다.

Correlation Analysis Results
피어슨 상관 계수의 절대값이 0.3 이상(강한 상관관계)인 요인들을 살펴보면, 4개 요인(‘평균연령(-0.537)’, ‘사망률(-0.487)’, ‘1인 가구의 비율(-0.316)’, ‘1세대 가구의 비율(-0.478)’)은 화재 발생 건수와 음의 상관관계를 가지는 것으로 나타났으며(r < -0.3), 11개 요인(‘인구(0.727)’, ‘출생아 수(0.725)’, ‘등록 외국인 수(0.598)’, ‘평균 가구원 수(0.429)’, ‘1인 가구의 수(0.649)’, ‘1세대 가구의 수(0.715)’, ‘2세대 가구의 비율(0.459)’, ‘2세대 가구의 수(0.698)’, ‘재혼 건수(0.789)’, ‘외국인 배우자 부부 혼인 건수(0.748)’와 ‘화재 인명피해 수(0.520)’는 양의 상관관계를 가지는 것으로 나타났다(r > 0.3). 특히, ‘인구’, ‘출생아 수’, ‘1세대 가구의 수’, ‘재혼 건수’, ‘외국인 배우자 부부 혼인 건수’는 매우 높은 양의 상관관계를 가지는 것으로 나타났다(r > 0.7). 다시말해, 상관분석결과 22개의 요인 중 15개 요인이 화재 발생 건수와 강한상관관계를 보이는 것으로 나타났으며(|r| > 0.3), 이 중 5개의 요인이 매우 높은 상관관계(|r| > 0.7)를 보이는 것으로 나타났다.
4. MLP 신경망 기반 화재 예측
4.1 모델 구축
본 연구는 화재 발생 건수를 예측하기 위해 데이터 준비부터 MLP 모델 구축, 모델 훈련, 모델 테스트, 결과 분석까지 5개의 단계로 이뤄진 화재 예측 프로세스를 Python 프로그램을 통해 수행했다(Figure 3).

Fire prediction process.
데이터 준비 단계(Step 1)에서는 수집된 데이터를 훈련/테스트 데이터로 구분하고, Min-Max 스케일링으로 데이터를 정규화하는 단계로, 2015년부터 2021년까지의 데이터가 훈련데이터로 활용되었고, 2022년 데이터는 모델의 효율성을 평가하기 위한 테스트 데이터로 활용되었다. 두 번째 단계(Step 2)는 MLP 모델의 클래스를 정의하고 입력 크기, 은닉층 크기, 출력 크기 등의 매개변수를 설정하는 단계로, 모델은 3.2절의 상관성 분석 결과를 바탕으로 상관계수의 절댓값이 0.3 이상인 15개 요인을 활용한 모델(Model 1)과 상관계수의 절댓값이 0.7보다 큰 5개의 요인을 활용한 모델(Model 2)로 구분하여 구축되었다. 모델의 입력층과 출력층 사이에 8개의 뉴런을 가진 은닉층이 포함되어 있으며, forward propagation을 통해 입력 데이터를 전 방향으로 전달하여 은닉층과 출력층을 생성했다. 모델 훈련 단계(Step 3)에서는 훈련 과정에서 여러 에포크(epochs)를 통해 입력 데이터가 은닉층 계산을 거쳐 은닉층의 출력이 생성되고, 그 후 출력층 계산을 통해 최종 예측 결과가 도출된다. 이러한 계산은 Sigmoid 활성화 함수와 가중치 행렬을 사용하여 이루어지는데, 식(2)와 식(3)을 통해 순전파(forward propagation)로 예측 결과를 생성하고, 역전파(back propagation)를 통해 손실 함수를 최소화하기 위한 가중치 업데이트를 수행한다.
1) 은닉층 출력:
여기서, 입력 데이터는 Sigmoid 활성화 함수를 통해 은닉층의 각 뉴런에 전달되며, X는 입력 데이터로 나타나며, Winput-hidden은 입력층에서 은닉층으로의 가중치를 의미한다.
2) 출력층 계산:
여기서 은닉층의 출력은 출력층의 가중치와 함께 Sigmoid 활성화 함수를 거쳐 최종 예측값을 도출한다. y’는 모델의 예측 출력을 의미하며, Whidden-output은 은닉층에서 출력층으로의 가중치를 나타낸다. 학습 과정에서 데이터를 10,000번 반복해서 사용하며 에포크가 많을수록 모델은 데이터를 더 많이 학습하게 되지만, 과적합의 위험이 있어 드롭아웃(dropout) 기법을 통해 훈련 시 일부 은닉층 뉴런을 무작위로 제거하여 과적합을 방지하고 모델의 일반화 성능을 향상했다. 모델 테스트 단계(Step 4)에서는 훈련된 모델을 사용하여 테스트 데이터를 예측하고, 예측 결과와 실제 결과를 시각화하여 성능을 비교했다. 마지막 결과 분석 단계(Step 5)에서는 절대 백분율 오차(mean absolute percentage error, MAPE), 평균 절대 오차(mean absolute error, MAE), 평균 제곱근 오차(root mean squared error, RMSE) 성능지표를 통해 모델을 성능 비교한다. 여기서, MAPE는 오차를 실제값으로 나눈 백분위 값을 의미하며, 모델의 상대적인 오차를 의미한다. MAPE는 성능을 직관적으로 확인할 수 있다는 장점을 갖지만, 실제값과 예측값이 0에 가까울수록 불안정하다는 한계를 가진다. MAP는 평균적인 예측 오차 크기를 나타내며 예측값과 실제값 간의 절대적인 오차를 측정한다. 하지만 MAE는 오차의 방향성이 고려되지 않는다는 한계를 가진다. 마지막으로 RMSE는 예측값과 실제값 간의 분석으로, 예측오차간의 표준편차를 의미한다. RMSE는 큰 값이 계산 전체에 지나친 영향을 미치지 못하게 제어한다는 장점을 갖지만, 이상값에 매우 민감하다는 한계를 가진다. 본 논문에서는 각 단일 지표가 가지는 한계를 극복하기 위해 MAPE, MAE 및 RMSE를 함께 사용하여 다차원적으로 모델의 성능을 평가하고자 한다(10-14).
4.2 화재 예측 결과 및 모델 성능 비교분석
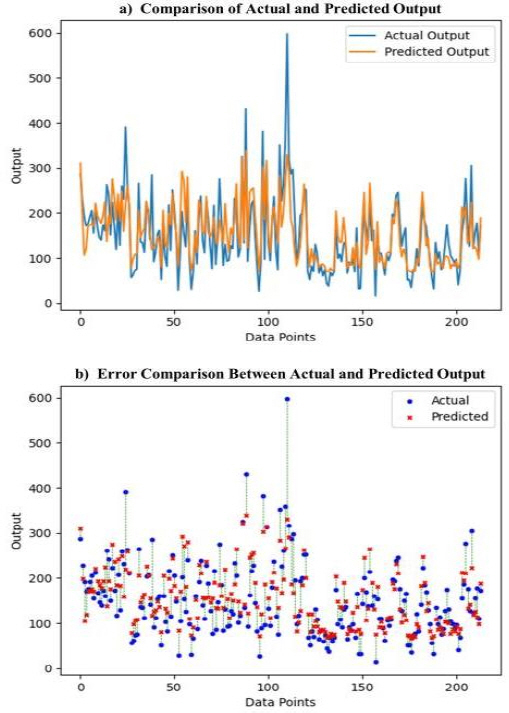
MLP 기반 화재발생예측 모델의 결과는 Figures 4, 5와 같다. 모델별로 입력변수 15개와 5개를 활용하여 2022년 1월 1일부터 12월 31일까지의 지역(시⋅군⋅구)별 화재 발생 건수를 보여주며, Figures 4(a), 5(a)의 파란색 선은 실측값, 주황색 선은 모델의 예측값을 의미한다. Figures 4(b), 5(b)는 데이터 포인트에 따른 예측값과 실제값의 시각적 차이를 보여주는 그림이며, x축은 개별 데이터 포인트를, y축은 해당 데이터 포인트의 출력값(화재 발생 건수)을 나타낸다. 이때 파란색 점은 실제 화재 발생 건수를 빨간색 점은 모델이 예측한 값을 보여준다. 각 점은 데이터셋 내의 한 관측치를 대표하며, 이를 통해 모델의 예측값과 실제값의 일치 정도를 파악할 수 있다. 녹색 선은 각 데이터 포인트에서의 예측 오차를 시각화한 선으로, 실제 화재 발생 건수와 모델이 예측한 건수 간의 차이를 나타낸다.

Prediction results for Model 1 (15 ea).
Prediction results for Model 2 (5 ea).
Model 1의 경우, 일부 표본에 대한 모델의 예측은 실제 값과 매우 유사하여 비교적 좋은 예측 추세를 보여주었다. 최소 오차 표본은 실제 값이 8건이었고 모델은 23.86건으로 예측하여 15.86의 오차가 발생했다. 반면에 최대 오차 표본은 실제 값이 646건이었고 모델은 497건으로 예측하여 149건의 오차를 보이는 것으로 나타났다.
5개 입력변수를 사용한 Model 2의 경우 양의 편향을 보이며, 즉 실제값보다 예측값이 조금 높은 경향을 보였다(Figure 5(a)). 최대 예측 오차 표본에서 예측값 432건은 실제값 598건과 166건의 오차가 발생했지만, 최소 예측 오차는 실제값 15건, 예측값 32건으로 17건으로 나타났다.
Model 1과 Model 2의 MAPE, MAE, RMSE를 분석한 결과는 Table 3과 같다.

Performance Comparison Results
MAPE 값은 Model 1은 26.37%, Model 2는 30.92%로, Model 1은 실제값과 26.37%의 오차, Model 2는 실제값과 30.92%의 오차를 보이는 것으로 나타났다. MAE값은 Model 1은 33.77, Model 2는 36.16으로 나타나, Model 1의 예측 화재건수는 실제 화재 건수와 평균 33.77건의 차이를 보이며, Model 2의 경우 평균 36.16건의 차이를 보이는 것으로 나타났다. 분석에 활용된 지역(시⋅군⋅구)별 평균 화재건수가 164.66건이라는 것을 고려하였을 때 두 모델이 보이는 보인 MAE 값은 수용 가능한 범위로 판단된다. 마지막으로 RMSE 값은 Model 1은 48.69, Model 2는 48.61로 Model 2의 예측성능이 더 높게 나타났다. 최종적으로 두 모델 모두 약 30% 오차 내에서 화재 발생 건수의 예측이 가능한 것으로 나타났다.
본 논문에서 개발된 화재 예측 모델은 사회지표를 활용하여 시⋅군⋅구 지역에서 발생할 수 있는 화재건수를 예측함으로써 지역단위의 화재예방전략 및 관리방안 수립(15,16), 지역의 소방대 배치계획 수립(3), 화재취약지역의 분류(17)의 근거자료로 활용될 수 있을 것으로 기대된다. 구체적으로 본 논문에서 제시하는 화재 예측 모델은 지역의 ‘연령’, ‘외국인 수’ 등을 포함한 사회지표를 고려하여 제시되었기 때문에 지역의 사회경제적⋅인구통계학적 요인에 따른 화재위험성을 반영하여 화재 발생을 예측한다는 장점을 가지며, 이는 지역단위의 화재예방전략, 관리방안 수립의 근거 자료로 활용될 수 있다는 것을 의미한다. 더 나아가 지역의 사회경제적⋅인구통계학적 요인을 고려한 화재취약지역의 분류와 효율적인 소방대 배치계획의 근거로 활용될 수 있을 것으로 기대된다.
5. 결 론
본 연구에서는 도시의 사회경제적⋅인구통계학적 요인이 화재 발생에 미치는 영향을 분석하고 각 요인에 따른 화재 발생을 예측하기 위해 ‘한국의 사회지표’와 화재의 상관관계를 분석하고, 이를 바탕으로 다층퍼셉트론(MLP) 기반 화재 예측 모델을 구축하였다.
상관분석 결과, 도시의 ‘평균연령’, ‘사망률’, ‘1인 가구의 비율’, ‘1세대 가구의 비율’, ‘인구’, ‘출생아 수’, ‘등록 외국인 수’, ‘평균 가구원 수’, ‘1인 가구의 수’, ‘1세대 가구의 수’, ‘2세대 가구의 비율’, ‘2세대 가구의 수’, ‘재혼 건수’, ‘외국인 배우자 부부 혼인 건수’와 ‘화재 인명피해 수’와 도시의 화재 발생 건수가 상관관계를 보이는 것으로 나타났다.
이후 상관계수의 값을 기준으로 상관계수의 절댓값이 0.3 이상인 15개 요인을 활용한 모델(Model 1)과 상관계수의 절댓값이 0.7 이상인 5개의 요인을 활용한 모델(Model 2)로 구분하여 MLP 모델을 구축하고, 그 성능을 검토한 결과, Model 1은 실제값과 26.37%의 오차를 보이며, Model 2는 실제값과 30.92%의 오차를 보이는 것으로 나타났다.
본 논문의 결과는 사회지표를 활용한 화재 예측의 가능성을 보여주었다는 데 그 의의가 있으며, 개발된 예측모델은 지역단위의 화재예방전략수립, 소방대 배치계획 수립, 화재취약지역의 분류 등에 활용될 수 있을 것으로 기대된다. 하지만, 제시된 모델들의 오차는 30% 수준으로 나타났기 때문에, 향후 예측정확도를 높이기 위해 시⋅군⋅구 단위 데이터의 부재와 결측값으로 인해 본 논문에서 고려되지 못한 255개 사회지표에 대한 데이터 수집 및 분석과 함께, 시⋅군⋅구 단위의 건물데이터와 같은 추가적인 지표를 고려한 연구가 필요할 것으로 판단된다. 또한 단순히 화재의 발생건수에 대한 예측이 아닌 화재의 발생원인, 발생장소 등을 고려한 추가연구가 필요할 것으로 판단된다.
후 기
이 논문은 2023년도 정부(교육부)의 재원으로 한국연구재단의 지원을 받아 수행된 기초연구사업임(No. RS-2023-00242004).